はじめに
kossyです。「T3 Stack 完全に理解した」と言いたいんですが、まだ完全に理解するところにすら辿り着けておらず、焦りを感じています。
今回は、 NextAuth + GitHub OAuth で 認証機能をまずはローカル環境で動かせるところまで実装してみます。
環境
node 20.10.0
npm 10.2.3
next.js 14.0.4
trpc 10.43.6
next-auth 4.24.5
prisma 5.6.0
Oauth Appの作成
以下URLを参考に作成してください。作成する際、Email addresses に Read-only permissionを付与し、 callback URLには
http://localhost:3000/api/auth/callback/github
を指定してください。
Email addresses に Read-only permissionを付与する背景については公式ドキュメントで解説されています。
When creating a GitHub App, make sure to set the "Email addresses" account permission to read-only in order to access private email addresses on GitHub. GitHub アプリを作成するときは、GitHub 上のプライベート メール アドレスにアクセスできるように、 「メール アドレス」アカウントの権限を読み取り専用に設定してください。
OAuth App が作成されたら、Generate a new client secret ボタンを押して secret key を作成し、
Client ID と secret key を控えておいてください。(後ほど .env にIDとKeyを記載するため)
コードの修正
以下のファイルの修正が必要なので、手順を解説します。
- src/server/auth.tsの修正
- .envおよび src/env.jsの修正
1. src/server/auth.tsの修正
GitHubProviderのimportが必要なので、追加します。
import { PrismaAdapter } from "@next-auth/prisma-adapter"; import { getServerSession, type DefaultSession, type NextAuthOptions, } from "next-auth"; import GitHubProvider from "next-auth/providers/github"; // <= 追加
また、authOptionsオブジェクトのprovidersオブジェクトも修正が必要です。
providers: [ DiscordProvider({ clientId: env.DISCORD_CLIENT_ID, clientSecret: env.DISCORD_CLIENT_SECRET, }), GitHubProvider({ clientId: env.GITHUB_CLIENT_ID, clientSecret: env.GITHUB_CLIENT_SECRET, }),
2. .envおよび src/env.jsの修正
.envにGitHubのIDとTokenを記載してください。(ここで貼っているのはサンプル値です)
# Next Auth Discord Provider から下の定義の部分は消してOKです。
# Next Auth Github Provider GITHUB_CLIENT_ID="YOUR_CLIENT_ID" GITHUB_CLIENT_SECRET="YOUR_CLIENT_SECRET"
今の状態だとApp内で env.GITHUB_CLIENT_ID のように呼び出すことができない(型エラーになります)ため、env.jsの修正を行います。
export const env = createEnv({ /** * Specify your server-side environment variables schema here. This way you can ensure the app * isn't built with invalid env vars. */ server: { DATABASE_URL: z .string() .refine( (str) => !str.includes("YOUR_MYSQL_URL_HERE"), "You forgot to change the default URL" ), NODE_ENV: z .enum(["development", "test", "production"]) .default("development"), NEXTAUTH_SECRET: process.env.NODE_ENV === "production" ? z.string() : z.string().optional(), NEXTAUTH_URL: z.preprocess( // This makes Vercel deployments not fail if you don't set NEXTAUTH_URL // Since NextAuth.js automatically uses the VERCEL_URL if present. (str) => process.env.VERCEL_URL ?? str, // VERCEL_URL doesn't include `https` so it cant be validated as a URL process.env.VERCEL ? z.string() : z.string().url() ), DISCORD_CLIENT_ID: z.string(), DISCORD_CLIENT_SECRET: z.string(), GITHUB_CLIENT_ID: z.string(), // 追加 GITHUB_CLIENT_SECRET: z.string(), // 追加 }, 中略 /** * You can't destruct `process.env` as a regular object in the Next.js edge runtimes (e.g. * middlewares) or client-side so we need to destruct manually. */ runtimeEnv: { DATABASE_URL: process.env.DATABASE_URL, NODE_ENV: process.env.NODE_ENV, NEXTAUTH_SECRET: process.env.NEXTAUTH_SECRET, NEXTAUTH_URL: process.env.NEXTAUTH_URL, DISCORD_CLIENT_ID: process.env.DISCORD_CLIENT_ID, DISCORD_CLIENT_SECRET: process.env.DISCORD_CLIENT_SECRET, GITHUB_CLIENT_ID: process.env.GITHUB_CLIENT_ID, // 追加 GITHUB_CLIENT_SECRET: process.env.GITHUB_CLIENT_SECRET, // 追加 },
動作確認
npm run dev で 開発サーバーを立ち上げて、 http:localhost:3000 にアクセスすると、以下の画面が表示されます。

Sign in ボタンを押すと、 http://localhost:3000/api/auth/signin に遷移し、ログインのボタンが2つ表示されます。
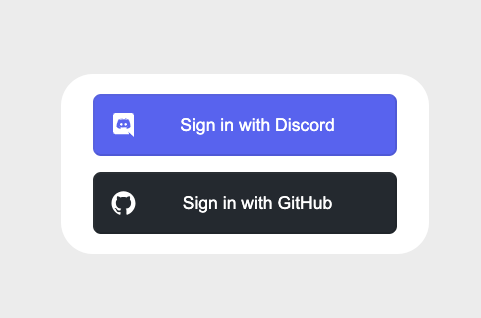
今回はGitHub OAuthのテストですので、Sign in with GitHub のボタンを押してください。
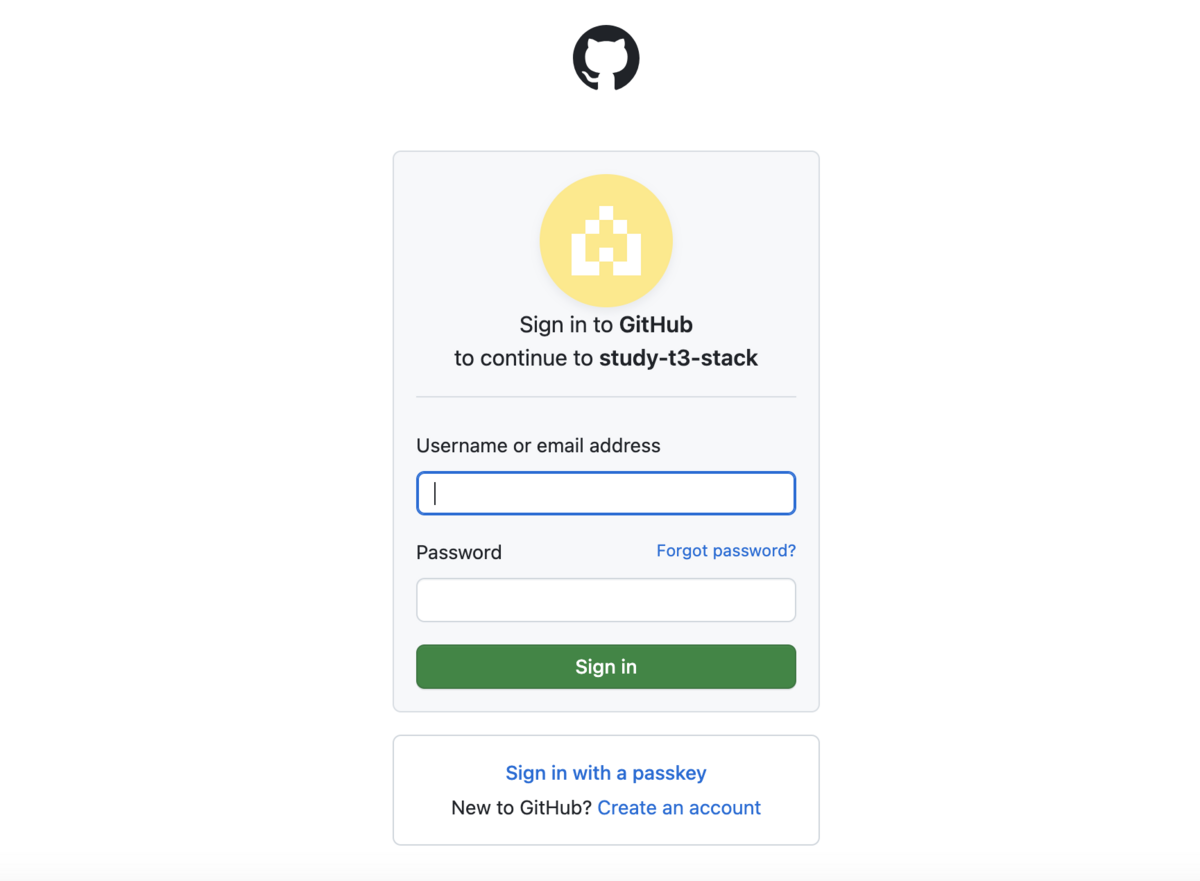
GitHubのログイン画面に遷移するので、必要事項を入力し、 Sign in ボタンを押してください。
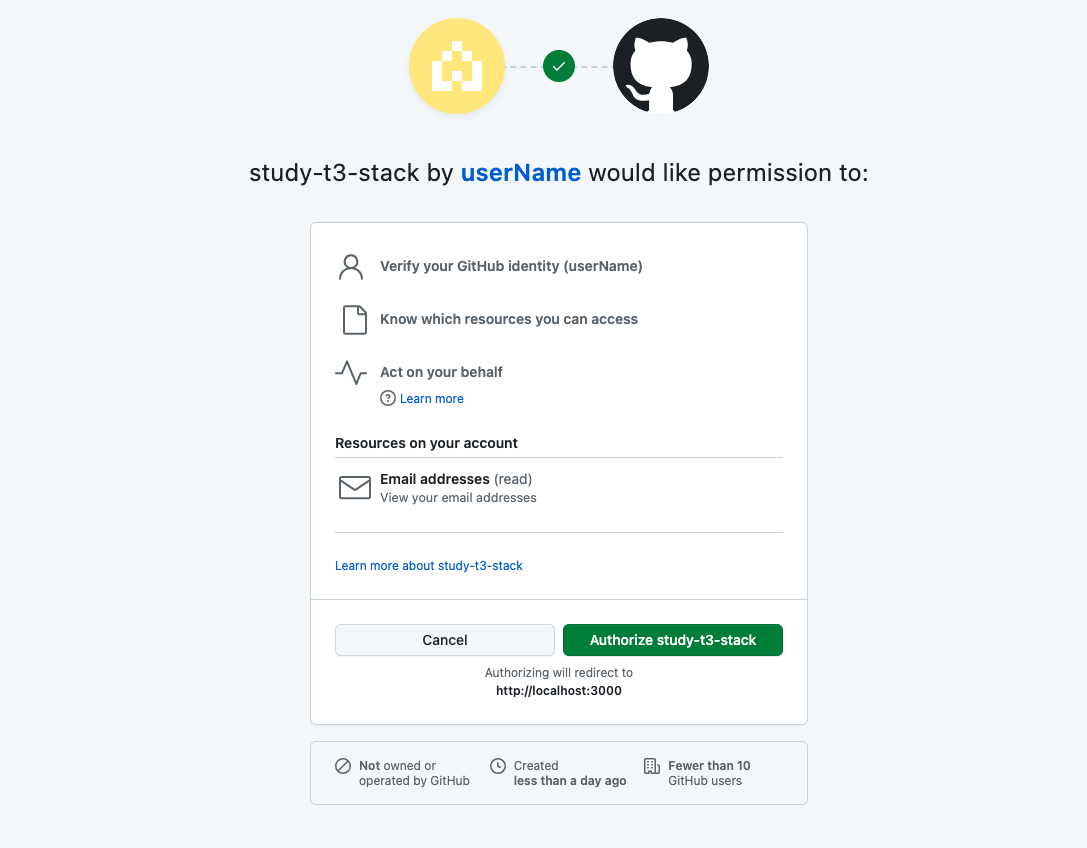
ログインに成功すると、認可の要求をされますので、 Authorize アプリ名 をクリックします。
認可処理が完了すると、T3 App のTOP画面にリダイレクトされます。
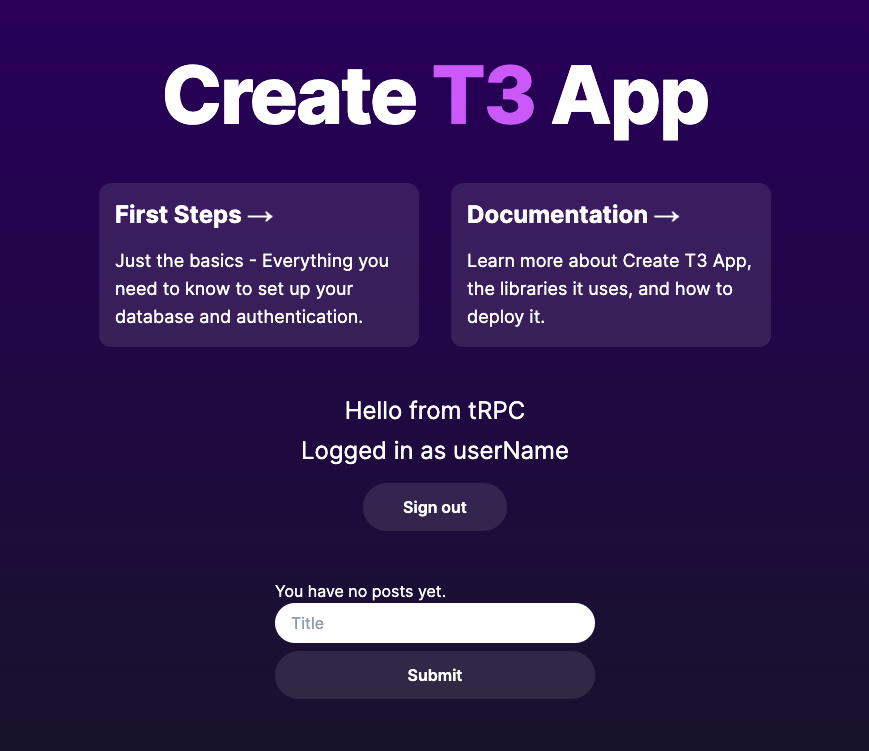
こんなに簡単に OAuth できていいのか!?というくらいアッサリ動きますね、、、
本番運用する際は OAuth Appの設定をより詳細に行わなければいけないので、それはまた別途記事にしたいと思います。
あとがき
認証ロジックの大部分がNextAuth内部で行われているため、かなりブラックボックスではありますね、、、
需要があれば NextAuth.js のコードリーディング記事でも書こうかしら。