create t3-app で NextAuth + GitHub OAuth で 認証機能を実装する
はじめに
kossyです。「T3 Stack 完全に理解した」と言いたいんですが、まだ完全に理解するところにすら辿り着けておらず、焦りを感じています。
今回は、 NextAuth + GitHub OAuth で 認証機能をまずはローカル環境で動かせるところまで実装してみます。
環境
node 20.10.0
npm 10.2.3
next.js 14.0.4
trpc 10.43.6
next-auth 4.24.5
prisma 5.6.0
Oauth Appの作成
以下URLを参考に作成してください。作成する際、Email addresses に Read-only permissionを付与し、 callback URLには
http://localhost:3000/api/auth/callback/github
を指定してください。
Email addresses に Read-only permissionを付与する背景については公式ドキュメントで解説されています。
When creating a GitHub App, make sure to set the "Email addresses" account permission to read-only in order to access private email addresses on GitHub. GitHub アプリを作成するときは、GitHub 上のプライベート メール アドレスにアクセスできるように、 「メール アドレス」アカウントの権限を読み取り専用に設定してください。
OAuth App が作成されたら、Generate a new client secret ボタンを押して secret key を作成し、
Client ID と secret key を控えておいてください。(後ほど .env にIDとKeyを記載するため)
コードの修正
以下のファイルの修正が必要なので、手順を解説します。
- src/server/auth.tsの修正
- .envおよび src/env.jsの修正
1. src/server/auth.tsの修正
GitHubProviderのimportが必要なので、追加します。
import { PrismaAdapter } from "@next-auth/prisma-adapter"; import { getServerSession, type DefaultSession, type NextAuthOptions, } from "next-auth"; import GitHubProvider from "next-auth/providers/github"; // <= 追加
また、authOptionsオブジェクトのprovidersオブジェクトも修正が必要です。
providers: [ DiscordProvider({ clientId: env.DISCORD_CLIENT_ID, clientSecret: env.DISCORD_CLIENT_SECRET, }), GitHubProvider({ clientId: env.GITHUB_CLIENT_ID, clientSecret: env.GITHUB_CLIENT_SECRET, }),
2. .envおよび src/env.jsの修正
.envにGitHubのIDとTokenを記載してください。(ここで貼っているのはサンプル値です)
# Next Auth Discord Provider から下の定義の部分は消してOKです。
# Next Auth Github Provider GITHUB_CLIENT_ID="YOUR_CLIENT_ID" GITHUB_CLIENT_SECRET="YOUR_CLIENT_SECRET"
今の状態だとApp内で env.GITHUB_CLIENT_ID のように呼び出すことができない(型エラーになります)ため、env.jsの修正を行います。
export const env = createEnv({ /** * Specify your server-side environment variables schema here. This way you can ensure the app * isn't built with invalid env vars. */ server: { DATABASE_URL: z .string() .refine( (str) => !str.includes("YOUR_MYSQL_URL_HERE"), "You forgot to change the default URL" ), NODE_ENV: z .enum(["development", "test", "production"]) .default("development"), NEXTAUTH_SECRET: process.env.NODE_ENV === "production" ? z.string() : z.string().optional(), NEXTAUTH_URL: z.preprocess( // This makes Vercel deployments not fail if you don't set NEXTAUTH_URL // Since NextAuth.js automatically uses the VERCEL_URL if present. (str) => process.env.VERCEL_URL ?? str, // VERCEL_URL doesn't include `https` so it cant be validated as a URL process.env.VERCEL ? z.string() : z.string().url() ), DISCORD_CLIENT_ID: z.string(), DISCORD_CLIENT_SECRET: z.string(), GITHUB_CLIENT_ID: z.string(), // 追加 GITHUB_CLIENT_SECRET: z.string(), // 追加 }, 中略 /** * You can't destruct `process.env` as a regular object in the Next.js edge runtimes (e.g. * middlewares) or client-side so we need to destruct manually. */ runtimeEnv: { DATABASE_URL: process.env.DATABASE_URL, NODE_ENV: process.env.NODE_ENV, NEXTAUTH_SECRET: process.env.NEXTAUTH_SECRET, NEXTAUTH_URL: process.env.NEXTAUTH_URL, DISCORD_CLIENT_ID: process.env.DISCORD_CLIENT_ID, DISCORD_CLIENT_SECRET: process.env.DISCORD_CLIENT_SECRET, GITHUB_CLIENT_ID: process.env.GITHUB_CLIENT_ID, // 追加 GITHUB_CLIENT_SECRET: process.env.GITHUB_CLIENT_SECRET, // 追加 },
動作確認
npm run dev で 開発サーバーを立ち上げて、 http:localhost:3000 にアクセスすると、以下の画面が表示されます。

Sign in ボタンを押すと、 http://localhost:3000/api/auth/signin に遷移し、ログインのボタンが2つ表示されます。
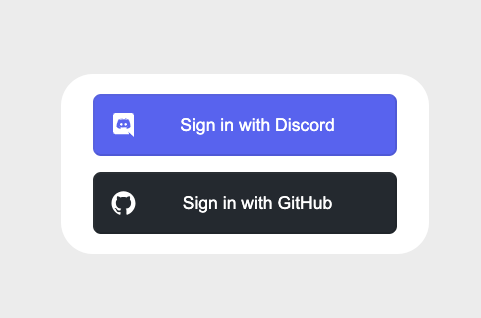
今回はGitHub OAuthのテストですので、Sign in with GitHub のボタンを押してください。
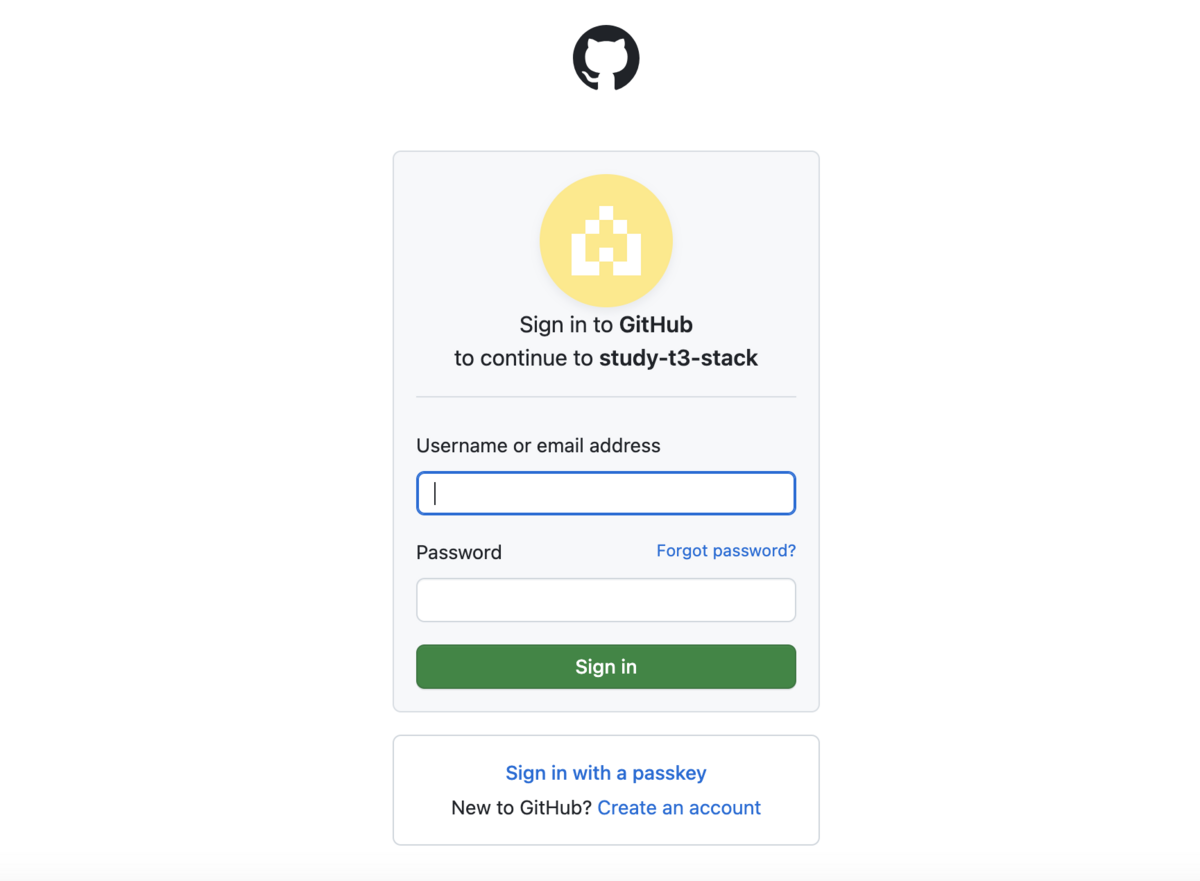
GitHubのログイン画面に遷移するので、必要事項を入力し、 Sign in ボタンを押してください。
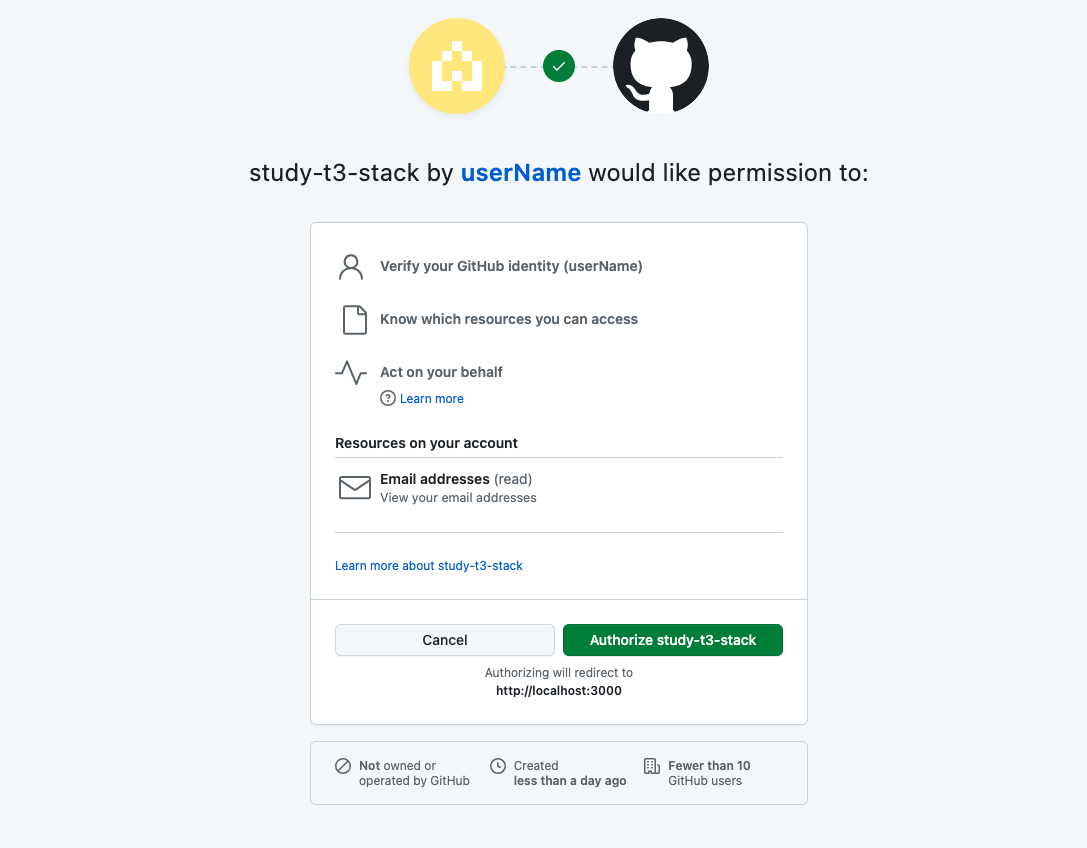
ログインに成功すると、認可の要求をされますので、 Authorize アプリ名 をクリックします。
認可処理が完了すると、T3 App のTOP画面にリダイレクトされます。
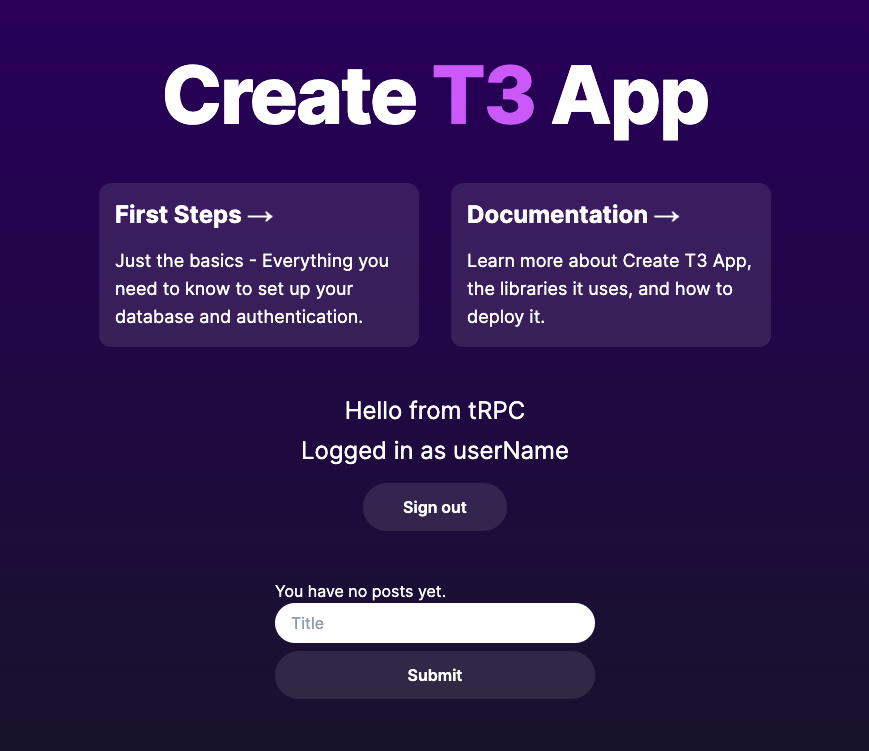
こんなに簡単に OAuth できていいのか!?というくらいアッサリ動きますね、、、
本番運用する際は OAuth Appの設定をより詳細に行わなければいけないので、それはまた別途記事にしたいと思います。
あとがき
認証ロジックの大部分がNextAuth内部で行われているため、かなりブラックボックスではありますね、、、
需要があれば NextAuth.js のコードリーディング記事でも書こうかしら。
nvm use の自動実行
はじめに
kossyです。nodeのバージョンをGlobalに変えたくない(そもそもDocker使え!!)時、ありませんか?
今回は、.nvmrcを用意し、ディレクトリを切り替えた時に自動で .nvmrcで指定したバージョンに切り替える方法を解説します。
環境
MacBookPro Intel Core i5 nvm 0.34.0
結論
~/.bash_profile に以下のコードを追加
if [ -f ~/.bashrc ]; then . ~/.bashrc fi
そして ~/.bashrcに以下のコードを追加します。
cd_nvm_use() {
local nvmrc_path=".nvmrc"
if [[ -f "$nvmrc_path" && -r "$nvmrc_path" ]]; then
local nvmrc_node_version=$(cat "$nvmrc_path")
local current_node_version=$(node -v | sed 's/^v//')
if [[ "$nvmrc_node_version" != "$current_node_version" ]]; then
nvm use || echo "Error: nvm use failed"
fi
fi
}
export PROMPT_COMMAND="cd_nvm_use; $PROMPT_COMMAND"
解説
.bash_profile
// if ステートメントは条件式が真(true)の場合に、後に続くコマンドを実行 if [ -f ~/.bashrc ]; then . ~/.bashrc // . (ドット) コマンドは別名 source コマンドであり、指定されたファイルの内容を現在のシェルコンテキストで実行する。この場合、.bashrc ファイルが存在する場合、その内容が現在のシェルセッションに読み込まれ、実行される。 fi
この設定は、ログインシェルおよび非ログインシェルの間で設定を共有するのが目的です。
このコードにより、ログイン時にもこれらのカスタマイズが適用されるようになります。
.bashrc
cd_nvm_use() {
local nvmrc_path=".nvmrc"
if [[ -f "$nvmrc_path" && -r "$nvmrc_path" ]]; then
local nvmrc_node_version=$(cat "$nvmrc_path")
local current_node_version=$(node -v | sed 's/^v//')
if [[ "$nvmrc_node_version" != "$current_node_version" ]]; then
nvm use || echo "Error: nvm use failed"
fi
fi
}
export PROMPT_COMMAND="cd_nvm_use; $PROMPT_COMMAND"
ディレクトリを移動するたびに、そのディレクトリ内に .nvmrc ファイルが存在するかどうかを確認し、
存在する場合はそのファイルに指定された Node.js のバージョンを使うように nvm use コマンドを実行するようにしています。
あとがき
Create T3 App で作成された layout.tsxのコードを読んでみる
はじめに
kossyです。やはり人間には絶対にやらなければならないというプレッシャーが必要だと感じています。
今日は Create T3 App で作成された layout.tsxのコードを読んでみようと思います。
概要
npm create t3-app@latest して、 App Router を有効にすると、src/app/layout.tsx というファイルが作成されます。
このファイルは、App Routerの機能で、自動でどのコンポーネントでも呼ばれるファイルになっています。
公式ドキュメントは以下です。
コードリーディング
ChatGPTの助けを借りながら、一行ずつ読み進めていきましょう。
import
import "~/styles/globals.css"; import { Inter } from "next/font/google";
npm create t3-app@latest した時の、「Will you be using Tailwind CSS for styling?」に Yesと答えると、 globals.css がimportされます。
globals.cssの中身は以下で、
@tailwind base;
@tailwind components;
@tailwind utilities;
tailwindを使用するための定義が行われています。
import { Inter } from "next/font/google"; は InterというGoogleFontをimportしています。
Inter
const inter = Inter({ subsets: ["latin"], variable: "--font-sans", });
フォントの設定オプションをオブジェクトとして渡しており、
subsets: ["latin"]
上記はフォントの文字セットを指定し、
variable: "--font-sans"
上記はフォントの変数名を設定しています。 ここで指定された"--font-sans"は、CSS変数としてフォントを参照する際に使用され、 この変数をCSSファイル内で使用することで、Interフォントをページ上で使用できるようになります。
metadata
export const metadata = { title: "Create T3 App", description: "Generated by create-t3-app", icons: [{ rel: "icon", url: "/favicon.ico" }], };
HTMLのメタデータを定義している箇所です。layout.tsxファイル内ではどこからも参照されていませんが、titleを書き換えるときちんと反映されます。
before
![]()
after
// Update T3 App に書き換えて保存 export const metadata = { title: "Update T3 App", description: "Generated by create-t3-app", icons: [{ rel: "icon", url: "/favicon.ico" }], };
![]()
あとがき
zero config を謳っているだけあって、今回紹介した箇所以外にも隠蔽されているロジックが多くて解読がしんどいんですが、
引き続きじっくり読んでいきたいと思います。
next.config.jsのimagesの指定について調べてみた
kossyです。Next.js使いになるべく、必死でインプット中です。
まずはconfigファイルからだろう(異論は認めます)ということで、next.config.jsを触っている時に copilot にサジェストされた、imagesの指定について備忘録として残してみます。
以下はChatGPT(GPT-4)の回答です。
imagesオブジェクトは、Next.js アプリケーションの next.config.js ファイル内で使用され、 画像の最適化設定をカスタマイズします。 具体的には、images オブジェクト内の domains 配列に指定されたドメインからの画像を Next.jsの画像最適化機能を使用して処理することを許可します。 この例では、avatars.githubusercontent.com というドメインからの画像が最適化の対象になります。 Next.js の画像最適化機能は、<Image /> コンポーネントを介して提供されます。 このコンポーネントは、画像を自動的に最適化し、 ロード時間を短縮し、パフォーマンスを向上させます。 しかし、デフォルトでは、Next.js は同一のオリジンから提供される画像のみを最適化します。 そのため、外部のドメイン(例えば、画像ホスティングサービスやCDN)から提供される画像を最適化するには、 そのドメインを next.config.js の images.domains 配列に明示的に追加する必要があります。 この設定を行うことで、指定されたドメインからの画像は、 Next.js によって自動的に最適化されるようになります。 画像は適切なサイズにリサイズされ、適切なフォーマット(例: WebP)に変換されることがあります。 これにより、ブラウザが必要とするサイズの画像をダウンロードし、 ページのロード時間を短縮し、ユーザー体験を向上させることができます。
最適化のための設定などができると言う理解で良さそうです。
ちなみに以下の記事を見ると、外部URLの画像を差し込むとエラーになるようです。
公式ドキュメントは以下で、domains以外にもremotePatternsの設定ができるようでした。 nextjs.org
module.exports = { images: { remotePatterns: [ { protocol: 'https', hostname: 's3.amazonaws.com', port: '', pathname: '/my-bucket/**', }, ], }, }
まずはChatGPT大先生の解説だけ頭に叩き込んでおけば良さそうです。
勉強になりました。
Rails・データベース・OSのTimeZoneの調べ方
必要に迫られタイトルに挙げたもののTimeZoneの調べ方をマスターしてしまったので、ブログに残しておきます。
# RailsのTimeZoneを調べる場合(コンソールからの調査) # config/application.rbの設定が返る Rails.application.config.time_zone => "Asia/Tokyo"
# データベースのTimeZoneを調べる場合(Railsコンソールからの調査) # PostgreSQLを使っている前提 ActiveRecord::Base.connection.execute("SHOW timezone").first["timezone"] => "Asia/Tokyo"
# OSのTimeZoneを調べる場合 # Linuxサーバー前提 timedatectl | grep "Time zone" => Time zone: Japan (JST, +0900)
upsert_all メソッドのオプションにrecord_timestamps: true を渡してバルクインサートすると、なぜか 時刻が18時間ズレるという問題に現在進行形で直面しておりまして、
色々調べたところ、record_timestamps: true だと DBの CURRENT_TIMESTAMP 関数が呼ばれてるようで、
ActiveRecord::Base.connection.execute("select current_timestamp;").first => {"current_timestamp"=>"2023-08-10T03:47:53.130-09:00"}
見事に18時間ズレている!というところまではわかったのですが、もう upsert_all ではなく activerecord-importのimportメソッドでバルクインサートしようかなと考え始めているところでした。
activerecord-importのimportメソッドであれば、created_atおよびupdated_atの値に、timestamp = default_timezone == :utc ? Time.now.utc : Time.now の返り値を採用しているため、
upsert_allにこだわることもないかなと考え始めていました。同じ問題に遭遇している方はいるのだろうか。
deviseのdestroyアクションを実行すると何が起こるか調べてみた
こんにちは!kossyです!
今回は、deviseのdestroyアクションを実行すると何が起こるか調べてみたので、備忘録としてブログに残してみたいと思います。
環境
Ruby 3.0.3
Rails 6.0.4
devise 4.8.1
前準備
pry-railsとpry-byebugをGemfileに記載してbundleした後、
sessions_controller.rbのdestroyアクションにbinding.pryを仕込みます。
25: def destroy 26: binding.pry 27: signed_out = (Devise.sign_out_all_scopes ? sign_out : sign_out(resource_name)) 28: set_flash_message! :notice, :signed_out if signed_out 29: yield if block_given? 30: respond_to_on_destroy 31: end
その後、適当なアカウントでログインして、ログアウトボタンを押してREPLを起動できたらOKです。
Devise.sign_out_all_scopes
From: /app/app/controllers/devise/sessions_controller.rb:27 Devise::SessionsController#destroy: 25: def destroy 26: binding.pry => 27: signed_out = (Devise.sign_out_all_scopes ? sign_out : sign_out(resource_name)) 28: set_flash_message! :notice, :signed_out if signed_out 29: yield if block_given? 30: respond_to_on_destroy 31: end > Devise.sign_out_all_scopes => true
Devise.sign_out_all_scopesはconfigファイルで設定できる値かと思われるので、見に行ってみます。
# Set this configuration to false if you want /users/sign_out to sign out # only the current scope. By default, Devise signs out all scopes. # config.sign_out_all_scopes = true
もし users/sign_out でサインアウトさせたい場合は false にする必要があるようです。
デフォルト値は true のようです。
「Deviseはすべてのスコープをサインアウトします。」と記載があるため、
例えば管理者権限と一般ユーザー権限の2つのモデルを作成し、両方の権限でログインしてからログアウトすると、全ての権限でログアウトになると思われます。
sign_out
def sign_out(resource_or_scope = nil) return sign_out_all_scopes unless resource_or_scope scope = Devise::Mapping.find_scope!(resource_or_scope) user = warden.user(scope: scope, run_callbacks: false) # If there is no user warden.logout(scope) warden.clear_strategies_cache!(scope: scope) instance_variable_set(:"@current_#{scope}", nil) !!user end
こちらはREPLで試しながら動作を確認してみます。
$ resource_or_scope
=> nil
このまま1行ずつ実行すると sign_out_all_scopes が実行されてしまうので、resource_or_scopeに値を入れた上で試してみます。
$ resource_or_scope = User.first $ scope = Devise::Mapping.find_scope!(resource_or_scope) => :user $ user = warden.user(scope: scope, run_callbacks: false) => #<User id: 1, ...> $ warden.logout(scope) => nil $ warden.clear_strategies_cache!(scope: scope) => {} $ instance_variable_set(:"@current_#{scope}", nil) => nil $ !!user => true
実際にsessionを削除するような処理はwardenの中で行っているようなので、wardenの処理にstepメソッドで入ってみたいと思います。
From: /usr/local/bundle/gems/warden-1.2.9/lib/warden/proxy.rb:267 Warden::Proxy#logout: 266: def logout(*scopes) => 267: if scopes.empty? 268: scopes = @users.keys 269: reset_session = true 270: end 271: 272: scopes.each do |scope| 273: user = @users.delete(scope) 274: manager._run_callbacks(:before_logout, user, self, :scope => scope) 275: 276: raw_session.delete("warden.user.#{scope}.session") unless raw_session.nil? 277: session_serializer.delete(scope, user) 278: end 279: 280: reset_session! if reset_session 281: end > scopes.empty? => false > user = @users.delete(scope) => #<User id: 1, ...> > raw_session => #<ActionDispatch::Request::Session:0x00007fb208019c00 ...>
raw_sessionおよびsession_serializerからsessionをdeleteして、
Railsのreset_session!メソッドを呼び出しているようです。
と思いきや、warden_compat.rbのメソッドらしいです。
> method(:reset_session!).source_location => ["/usr/local/bundle/gems/devise-4.8.0/lib/devise/rails/warden_compat.rb", 8]
module Warden::Mixins::Common def request @request ||= ActionDispatch::Request.new(env) end def reset_session! request.reset_session end def cookies request.cookie_jar end end
実際には ActionDispatch::Request クラスのreset_sessionメソッドが呼ばれているようです。
reset_session (ActionController::Base) - APIdock
raw_sessionについての知見が皆無なので調べてみます。
raw_session
先ほどstepで入った処理の中で色々実行してみました。
> raw_session.class => ActionDispatch::Request::Session > raw_session.methods => [:loaded?, :to_hash, :delete, :clear, :exists?, :to_h, ...] > raw_session.to_h => {"session_id"=>"b71549ad67aa9d67e27aa04fea2c0b37", "warden.user.user.key"=>[[1], "$2a$12$oLbqXNXAJ3P17TM.7bfaiu"], "warden.user.user.session"=>{"unique_session_id"=>"jj2nrehY8TNM-f_nrryY"}, "_csrf_token"=>"KbKDaYOjWm7jMLPfqctmdhG3ImpMGoQ4y9JX89plxLc="} > raw_session.method(:to_h).source_location => ["/usr/local/bundle/gems/actionpack-6.0.4.1/lib/action_dispatch/request/session.rb", 143]
action_dispatch/request/session.rb を見に行けばよさそう。
読んでもよくわからなかったので公式ドキュメントを見てみます、、、
Class: ActionDispatch::Request::Session — Documentation for rails (6.0.2.1)
Session is responsible for lazily loading the session from store.
セッションは、ストアからセッションを遅延ロードする責任があります。
出典: https://www.rubydoc.info/docs/rails/ActionDispatch/Request/Session
raw_sessionの役割についてはわかりましたが、定義元がよくわからないので調べてみます。
> method(:raw_session).source_location => ["/usr/local/bundle/gems/warden-1.2.9/lib/warden/mixins/common.rb", 9]
# Convenience method to access the session # :api: public def session env['rack.session'] end # session # Alias :session to :raw_session since the former will be user API for storing scoped data. alias :raw_session :session
env['rack.session']の返り値だったみたいです。
rack.sessionに値が書き込まれるタイミングはいつなのか?が気になりますが、返り値も定義元も役割もわかったので一旦ここまでにします。
session_serializerもいまいちわからんので調べます。
session_serializer
> session_serializer => #<Warden::SessionSerializer:0x00007f99501d5790 ... > method(:session_serializer).source_location => ["/usr/local/bundle/gems/warden-1.2.9/lib/warden/proxy.rb", 50]
def session_serializer @session_serializer ||= Warden::SessionSerializer.new(@env) end
コメントアウト部分を訳してみます。
Points to a SessionSerializer instance responsible for handling everything related with storing, fetching and removing the user session.
ユーザーセッションの保存、フェッチ、および削除に関連するすべての処理を担当するSessionSerializerインスタンスを指します。
出典: https://github.com/wardencommunity/warden/blob/master/lib/warden/proxy.rb#L46
CRUD全てを担当するクラスっぽいですね。定義元を見に行ってみます。
deleteメソッドの中身を見てみます。
def delete(scope, user=nil) session.delete(key_for(scope)) end # We can't cache this result because the session can be lazy loaded(セッションを遅延ロードするためにキャッシュを行いません) def session env["rack.session"] || {} end def key_for(scope) "warden.user.#{scope}.key" end
deleteメソッドはsessionから warden.user.user.key のようなkeyをdeleteするメソッドでした。
先ほど、「rack.sessionに値が書き込まれるタイミングはいつなのか?」と疑問を書いていましたが、storeメソッドが書き込んでいそうなので処理を追ってみます。
def store(user, scope) return unless user method_name = "#{scope}_serialize" specialized = respond_to?(method_name) session[key_for(scope)] = specialized ? send(method_name, user) : serialize(user) end
storeメソッドの呼び出し元がこちらでした。
def set_user(user, opts = {}) scope = (opts[:scope] ||= @config.default_scope) # Get the default options from the master configuration for the given scope opts = (@config[:scope_defaults][scope] || {}).merge(opts) opts[:event] ||= :set_user @users[scope] = user if opts[:store] != false && opts[:event] != :fetch options = env[ENV_SESSION_OPTIONS] if options if options.frozen? env[ENV_SESSION_OPTIONS] = options.merge(:renew => true).freeze else options[:renew] = true end end session_serializer.store(user, scope) end run_callbacks = opts.fetch(:run_callbacks, true) manager._run_callbacks(:after_set_user, user, self, opts) if run_callbacks @users[scope] end
set_userは_perform_authenticationというprivateメソッドで呼ばれています。
なので、「rack.sessionに値が書き込まれるタイミングはいつなのか?」という問いは、「_perform_authenticationメソッドでset_userが呼ばれた時」が一つの解かと思います。
ログアウトのことを調査していたのにログイン時の挙動の調査をしてしまいました、、、寄り道はここまでにします。
まとめ
destroyアクションが呼ばれると、
「Devise.sign_out_all_scopesが true なら、
全てのdeviseを使っている認証中のモデルのwardernのsessionを削除し、
falseなら引数に与えられたresourceのモデルのwardenのsessionを削除」
していました。
「wardenのsessionを削除」は、Warden::Proxy#logout メソッドが呼ばれていて、
内部では request.env['rack.session'].clear を呼んでsessionの中身をnilにすることでログアウトを実現してました。
今までログアウトについて、cookie初期化してsession削除してるんだろうな、程度の曖昧な理解に留まっていましたが、実際に処理を追ってみることで、
ログアウトの詳細な動作とwardenの仕組みの一端を理解することができました。
認証周りのコードを読めば読むほど、自分で認証周りを自作してはいけない気持ちになりますね。
devise-securityのparanoid_verificationのソースコードを追ってみた
こんにちは!kossyです!
今回はdevise-securityのparanoid_verificationのソースコードを追ってみたので、備忘録としてブログに残してみたいと思います。
paranoid_verificationってなに?
paranoid_verification モジュールは、「アプリケーションの管理者がいつでも、ユーザーが自分自身を確認するように強制できる」機能です。
以下のPRが paranoid_verification モジュールが実装された時のものです。
devise_security gem は メンテの止まった devise_security_extension Gemから公式にforkされたGemのため、blameしてもPRまで遡るのができないコードがあります。
paranoid_verification はform前の実装だったので、devise-security-extension gemの過去のPRを見たところ、以下の記載がありました。
Basically I got requirement for one application that "reset password" links should be additional verified after user set his Password.
He should call application support team and they will give him verification code. (hardcore security)But another usage of this feature is that at any point admin of application can enforce that user should verify himself.
so the feature: Generate (paranoid) verification code and enforce user to fill in verification code.
Until then user wont be able to use the application (similar functionality of expired password)
基本的に、ユーザーがパスワードを設定した後、「パスワードのリセット」リンクを追加で確認する必要があるという1つのアプリケーションの要件がありました。
ユーザーはアプリケーションサポートチームに電話する必要があり、サポートチームはユーザーに確認コードを与えます。 (ハードコアセキュリティ)ただし、この機能のもう1つの使用法は、アプリケーションの管理者がいつでも、ユーザーが自分自身を確認するように強制できることです。
そのため、機能: paranoid verification code を生成し、ユーザーに検証コードの入力を強制します。
それまでは、ユーザーはアプリケーションを使用できません(期限切れのパスワードと同様の機能)出典: https://github.com/phatworx/devise_security_extension/pull/117
「アプリケーションの管理者がいつでも、ユーザーが自分自身を確認するように強制したい」という要件がある場合は、このモジュールを有効活用できそうですね。
コードリーディング
上記の機能をどのように実現しているのでしょうか。実際にコードを読んでコンソールで実行しつつ仕様の理解を進めてみます。
need_paranoid_verification?
def need_paranoid_verification? !!paranoid_verification_code end
paranoid_verificationを使う際にテーブルに追加する必要のあるカラムである paranoid_verification_code の値の有無をBooleanで返却するメソッドでした。
用途としてはメソッド命名的に検証コードを実行する必要があるかどうか?を判定するために用いるためかと。
generate_paranoid_code
def generate_paranoid_code update_without_password paranoid_verification_code: Devise.verification_code_generator.call(), paranoid_verification_attempt: 0 end
名前の通りparanoid_codeをgenerateし、レシーバーに保存するメソッドのようです。(updateするなら!をメソッド名につけるのが慣習的にいいと思うが)
Devise.verification_code_generator.call()の返り値は以下のように、5文字のランダムな文字列が返るようです。
$ Devise.verification_code_generator.call() => "c8e93" $ Devise.verification_code_generator.call() => "98102"
定義元は以下でした。
# captcha integration for confirmation form mattr_accessor :verification_code_generator @@verification_code_generator = -> { SecureRandom.hex[0..4] }
captcha向けに5文字の文字列を返しているんですね。なぜ5文字なんだろう、普通一時的な認証コードって6文字が一般的では?と思ったんですが、captcha向けなら納得です。
paranoid_attempts_remaining
def paranoid_attempts_remaining Devise.paranoid_code_regenerate_after_attempt - paranoid_verification_attempt end
あと何回検証コードの実行ができるかを返却するメソッドのように見えますが、コンソールで試してみます。
$ user = User.first $ user.paranoid_verification_attempt => 1 $ user.paranoid_attempts_remaining => 9 # config/devise-security.rbで設定できる値です(デフォルトは10) $ Devise.paranoid_code_regenerate_after_attempt => 10
verify_code
def verify_code(code) attempt = paranoid_verification_attempt if (attempt += 1) >= Devise.paranoid_code_regenerate_after_attempt generate_paranoid_code elsif code == paranoid_verification_code attempt = 0 update_without_password paranoid_verification_code: nil, paranoid_verified_at: Time.now, paranoid_verification_attempt: attempt else update_without_password paranoid_verification_attempt: attempt end end
Devise.paranoid_code_regenerate_after_attemptで設定した値を上回っていない場合は generate_paranoid_code を実行して、
引数のcodeとparanoid_verification_codeが一致した場合は、
paranoid_verification_codeをnilで更新
paranoid_verified_atに現在時刻で更新
paranoid_verification_attemptに0で更新
をパスワード抜きで行っていました。
wikiを見てみる
wikiを見ると、locakbleで提供されているメソッドをオーバーライドして使うことを推奨しているようです。
lock after reset password One example of usage could be that after a user resets their password they need to contact support for the verification code. Just add to your authentication resource code similar to this: class User < ActiveRecord::Base # ... def unlock_access! generate_paranoid_code super end end
他にも管理者アカウントでロックする方法や検証コードの認証試行回数を表示する方法などが記載されていました。
勉強になりました。
Railsのbuild_associationの挙動がよくわからなかったので調べてみた
こんにちは!kossyです!
今回は、Railsのbuild_associationの挙動がよくわからなかったので調べてみました。
前提として、userがreservation(予約)を1つ持つという関連が組まれていることとします。この場合、userクラスのインスタンスメソッドとして自動的にbuild_reservationメソッドが定義されます。
ソースコードを見る
build_associationを定義しているのは singular_association.rb でした。
# Defines the (build|create)_association methods for belongs_to or has_one association def self.define_constructors(mixin, name) mixin.class_eval <<-CODE, __FILE__, __LINE__ + 1 def build_#{name}(*args, &block) association(:#{name}).build(*args, &block) end def create_#{name}(*args, &block) association(:#{name}).create(*args, &block) end def create_#{name}!(*args, &block) association(:#{name}).create!(*args, &block) end CODE end
class_evalで動的にメソッド定義を行ってますね。
では実際に呼び出される時はどのような挙動になるのでしょうか。試しにuserクラスに適当なインスタンスメソッドを定義して、binding.pryでdebugしてみましょう。
class User has_one :reservation def test_method binding.pry build_reservation end end
この状態でコンソールを開いて、userインスタンスに対してtest_methodを実行します。するとREPLが起動するので、stepメソッドでメソッド内部に移動すると、
lib/active_record/associations/builder/singular_association.rb:29 28: def build_#{name}(*args, &block) => 29: association(:#{name}).build(*args, &block) 30: end
動的にメソッド定義を行っている場所に辿り着きました。buildメソッドでインスタンス定義を行なっていると思われるので、処理を見てみます。
lib/active_record/associations/singular_association.rb:21 20: def build(attributes = {}, &block) => 21: record = build_record(attributes, &block) 22: set_new_record(record) 23: record 24: end
build_recordは実際に関連先のインスタンスを生成する処理かと思います。set_new_recordの処理も見てみます。
lib/active_record/associations/has_one_association.rb:75 74: def set_new_record(record) => 75: replace(record, false) 76: end
replaceメソッドの中身はこちら。
42: def replace(record, save = true) => 43: raise_on_type_mismatch!(record) if record 44: 45: return target unless load_target || record 46: 47: assigning_another_record = target != record 48: if assigning_another_record || record.has_changes_to_save? 49: save &&= owner.persisted? 50: 51: transaction_if(save) do 52: remove_target!(options[:dependent]) if target && !target.destroyed? && assigning_another_record 53: 54: if record 55: set_owner_attributes(record) 56: set_inverse_instance(record) 57: 58: if save && !record.save 59: nullify_owner_attributes(record) 60: set_owner_attributes(target) if target 61: raise RecordNotSaved, "Failed to save the new associated #{reflection.name}." 62: end 63: end 64: end 65: end 66: 67: self.target = record 68: end
いくつかのバリデーションを行った後、target(関連先のレコード)が既に存在していて、関連先のレコードが削除されておらず、新しい関連先のレコードがある場合、
remove_target!メソッドを呼んでいます。メソッド名から察するに、既に存在している関連先のレコードを削除するメソッドだと思いますが、処理を追ってみます。
78: def remove_target!(method) => 79: case method 80: when :delete 81: target.delete 82: when :destroy 83: target.destroyed_by_association = reflection 84: target.destroy 85: else 86: nullify_owner_attributes(target) 87: remove_inverse_instance(target) 88: 89: if target.persisted? && owner.persisted? && !target.save 90: set_owner_attributes(target) 91: raise RecordNotSaved, "Failed to remove the existing associated #{reflection.name}. " \ 92: "The record failed to save after its foreign key was set to nil." 93: end 94: end 95: end
私の実行環境だと引数のmethodは:destroyでした。
82行目で関連先のレコードに組まれたAssociationのレコードを削除し、83行目で関連先のレコードを削除しています。
まとめ
build_associationメソッドは、既に関連先のレコード(今回だとreservation)が存在する場合は、そのレコードを削除して新たなインスタンスを生成していました。更新時にbuild_associationを呼ぶ場合は挙動を頭に入れた上で実行した方がよさそうですね。(思わぬバグを誘発するかも)
Railsでddtraceを使う際に、Datadogのログに残すリクエストをフィルタリングしたい
こんにちは!kossyです!
さて、今回はDatadog の Ruby 用トレースクライアントであるddtrace gemで、Datadogのトレース対象とするリクエストをフィルタリングする方法について、ブログに残してみたいと思います。
環境
Rails 6.1.4
Ruby 2.7.6
ddtrace 1.4.1
実装方法
結論、以下のコードをconfig/initializers/datadog.rbに記載すればOKです。
Datadog::Pipeline.before_flush( Datadog::Pipeline::SpanFilter.new { |span| span.resource =~ /フィルタリングしたいControllerクラス/ }, )
例えばサーバーヘルスチェック用のAPIをトレース対象から除外したい場合は、
Datadog::Pipeline.before_flush( Datadog::Pipeline::SpanFilter.new { |span| span.resource =~ /HealthcheckController/ }, )
のように記載すればOKです。
複数のAPIをフィルタリングしたい場合
複数のクラスをトレース対象から除外したい場合は、「|」で繋いで記載すればOKです。
Datadog::Pipeline.before_flush( Datadog::Pipeline::SpanFilter.new { |span| span.resource =~ /HealthcheckController|PingController/ }, )
意図通り動くか、正規表現部分のチェックをしてみましょう。
# マッチした場合は0が返る "HealthcheckController" =~ /PingController|HealthcheckController/ => 0 # マッチしない場合はnilが返る "HealthcheckController" =~ /PingController/ => nil "HealthcheckController" =~ /HealthcheckController/ => 0
大いに参考にさせていただいたサイト
Dockerを使った開発時にpryやirbの履歴を保存したい
こんにちは!kossyです!
今回は開発環境にDockerを使ってRailsアプリを開発する際に、pryやirbの履歴を保存する方法についてブログに残してみたいと思います。
環境
Ruby 2.6.9
Rails 6.0.3
docker-compose version 1.27.0
docker-compose.ymlの編集
まずはdocker-compose.ymlを編集します。
# docker-compose.yml volumes: - history:/usr/local/history environment: IRB_HISTORY_PATH: /usr/local/history/.irb_history PRY_HISTORY_PATH: /usr/local/history/.pry_history
environmentにirbもpryも指定していますが、「普段使うデバッガだけ記載する」でもOKです。(複数人で開発する場合はいろんなデバッガを使われる可能性があるので複数記載するでもOK)
.irbrcの作成
irbをメインのデバッガとして使いたい場合は、アプリケーションのルートディレクトリ直下に.irbrcを作成します。
# .irbrc path = ENV['IRB_HISTORY_PATH'] if path IRB.conf[:HISTORY_FILE] = path end
ENV定数からirbの履歴を保存するパスを取得し、もしパスが設定されていれば、IRBクラスのconfigにパスを指定しています。
.pryrcの作成
pryをメインのデバッガとして使いたい場合は、アプリケーションのルートディレクトリ直下に.pryrcを作成します。
# .pryrc path = ENV['PRY_HISTORY_PATH'] if path Pry.config.history_file = path end
こちらも.irbrcとやっていることはほとんど一緒で、参照するパスと扱うクラスが違うだけですね。
IRB.confのソースコードを読んでみる
せっかくなので、IRBクラスのソースコードを読んでみましょうか。
docker-composeコマンドでコンテナを立てて rails c でコンソールを立ち上げて検証してみます。
# railsという名前のコンテナを立てる docker-compose run --rm rails bundle exec rails c
IRB.method(:conf).source_location => ["/usr/local/lib/ruby/2.6.0/irb.rb", 350]
source_locationを実行したところ、irb.rbの350行目にconfメソッドが生えているようです。
コメント部分の記述が詳しかったので、こちらを読んでみます。
# === History # # By default, irb will store the last 1000 commands you used in # <code>IRB.conf[:HISTORY_FILE]</code> (<code>~/.irb_history</code> by default). # # If you want to disable history, add the following to your +.irbrc+: # # IRB.conf[:SAVE_HISTORY] = nil #
デフォルトでは1000コマンドまで保存できて、IRB.conf[:HISTORY_FILE]に保存されるとのこと。(デフォルトは~/.irb_history)
また、履歴の保存をしたくない場合は、.irbrcに IRB.conf[:SAVE_HISTORY] = nil と記載すればOKとのこと。
irb.rbは約900行ほどのファイルなのですが、1/3はコメントが記載されてました。何ができるか知りたい場合は公式ドキュメントに加えて、コメント部分も読んでみるとよさそうです。
Pry.configのソースコードを読んでみる
次はPry.configのソースコードを確認してみましょうか。
Pry.config.method(:history_file).source_location => ["/bundle/ruby/2.6.0/gems/pry-0.13.1/lib/pry/config/attributable.rb", 13]
実際にhistory_fileの記載があったのはこちらのファイルでした。
# @return [String] attribute :history_file # 省略 history_file: Pry::History.default_file,
Pry::History.default_fileの定義はこちら。
def self.default_file history_file = if (xdg_home = Pry::Env['XDG_DATA_HOME']) # See XDG Base Directory Specification at # https://standards.freedesktop.org/basedir-spec/basedir-spec-0.8.html xdg_home + '/pry/pry_history' elsif File.exist?(File.expand_path('~/.pry_history')) '~/.pry_history' else '~/.local/share/pry/pry_history' end File.expand_path(history_file) end
ざっくり言うと基本的にはpry_historyというファイルに履歴が格納されていくコードになっていました。
もう一度.pryrcのコードを見てみます。
# .pryrc path = ENV['PRY_HISTORY_PATH'] if path Pry.config.history_file = path end
history_fileがattribute として定義されていて書き込みが可能になっているので、default_fileメソッドで定義されたファイルパスを.pryrcで上書きしていることになりますね。
おわりに
dockerの場合だとvolumeの設定をしないとコマンドの実行履歴が揮発してしまうので、一手間加えないとコマンドの実行履歴が保存されないんですね。(コンテナの中で全て完結するんだからそれはそう)